Modeling group actions on latent representations enables controllable transformations of high-dimensional
image data.
Prior works applying group-theoretic priors or modeling transformations typically operate in the
high-dimensional data space,
where group actions apply uniformly across the entire input, making it difficult to disentangle the subspace
that varies under transformations.
While latent-space methods offer greater flexibility, they still require manual partitioning of latent
variables into equivariant and invariant
subspaces, limiting the ability to robustly learn and operate group actions within the latent space. To
address this, we introduce a novel
end-to-end framework that for the first time learns group actions on latent image manifolds, automatically
discovering transformation-relevant
structures without manual intervention. Our method uses learnable binary masks with straight-through
estimation to dynamically partition latent
representations into transformation-sensitive and invariant components. We formulate this within a unified
optimization framework that jointly
learns latent disentanglement and group transformation mappings. The framework can be seamlessly integrated
with any standard encoder-decoder
architecture. We validate our approach on five 2D/3D image datasets, demonstrating its ability to
automatically learn disentangled latent factors
for group actions, while downstream classification tasks confirm the effectiveness of the learned
representations.
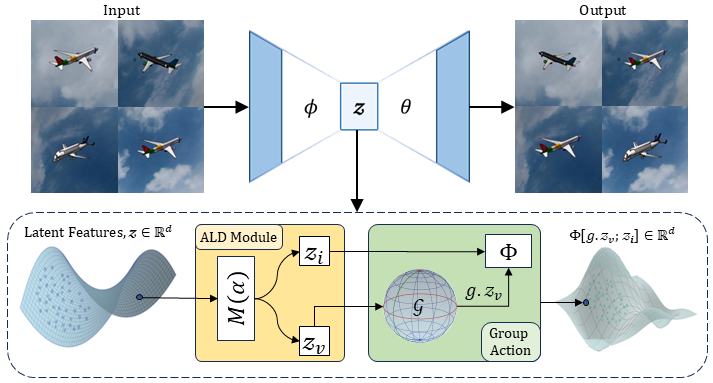
Our architecture employs an encoder–decoder framework with convolutional downsampling modules in the encoder
and corresponding upsampling modules in the decoder.
The latent representation

of an image

is
first partitioned into transformation variant (

) and
invariant (

) components using learnable binary masks (
)
) with straight-through
estimation.
The transformation variant (
) is then transformed using transformation corresponding to
the desired group action g.
The transformed

is combined with the invariant component
to
form the
transformed latent representation
)
which is sent to decoder to reconstruct the transformed
image.